
El mundo del File Fuzzing está lleno de una exhibición verdaderamente espectacular de pruebas. Es el último cambio en la inyección de software y merece la atención de cualquiera. Pero, ¿realmente sabes qué es el File Fuzzing? Hagamos un repaso rápido.
¿Qué es el File Fuzzing?
Fuzzing, también conocido como prueba de Fuzz, es una técnica de prueba de software de Black Hat que consiste en encontrar errores de implementación mediante el uso de inyección de datos malformados o semi-malformados de manera automatizada.
En otras palabras, es una técnica de aseguramiento de calidad que se utiliza para descubrir errores de codificación y brechas de seguridad en software, sistemas operativos y redes, e implica introducir grandes cantidades de datos aleatorios, llamados fuzz, al sujeto de prueba en un intento de encontrar sus fallos.
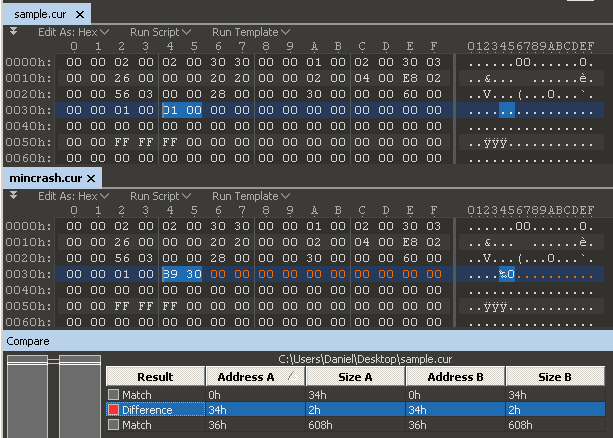
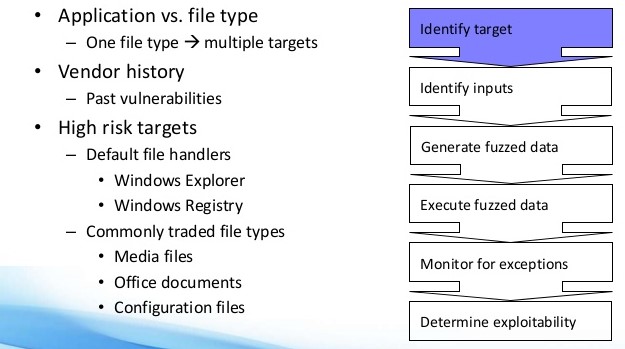
El fuzzing de formatos de archivo funciona de una manera en la que proporcionas a tu fuzzer una muestra de archivo legítima, después de lo cual el fuzzer puede mutar repetidamente la muestra y abrirla en la aplicación objetivo. Si la aplicación objetivo se bloquea, algo ha salido mal y el archivo mutado se guarda para su revisión en un momento posterior. Como el archivo original nunca bloquea la aplicación, pero el mutado sí lo hace, es posible que tengas algún tipo de control sobre el bloqueo. Si puedes controlar lo que se escribe, ejecuta y lee en la memoria, puedes tomar el control sobre el flujo de la aplicación. Si controlas el flujo de la aplicación, puedes hacer que la aplicación haga cualquier cosa, incluso cosas que nunca se suponía que debía hacer. Dicho esto, las pruebas de fuzzing pueden verse como una técnica automatizada de pruebas de software que implica proporcionar datos inválidos, inesperados o aleatorios como entradas a un programa informático.
Este programa puede, más adelante, ser monitoreado para excepciones incluyendo: fallos, fallos en las aserciones de código integradas, fugas de memoria, etc.
La implementación más común de los fuzzers es para probar programas que toman entradas estructuradas.
El fuzzer más efectivo generalmente genera entradas semi-válidas que son válidas en la forma en que no son inyectadas directamente por el analizador, pero crean comportamientos inesperados más profundos dentro del programa y son lo suficientemente inválidas para exponer casos extremos que no han sido tratados adecuadamente aún.
Un ejemplo de fuzzing de archivos:
import fuzzing
seed = "Esto podría ser el contenido de un enorme archivo de texto."
number_of_fuzzed_variants_to_generate = 10
fuzz_factor = 7
fuzzed_data = fuzzing.fuzz_string(seed, number_of_fuzzed_variants_to_generate, fuzz_factor)
print(fuzzed_data)Dónde se Originó el Fuzzing
Probar programas mediante la implementación de entradas aleatorias puede remontarse a la década de 1950, cuando los datos se almacenaban en tarjetas perforadas. Los programadores, más tarde, usarían estas tarjetas que se extraían de los mazos de tarjetas de números aleatorios como entrada para los programas de computadora. Si una ejecución revelaba algún comportamiento no deseado, se detectaba un error. Este es el ejemplo más antiguo y más primitivo de fuzzing de archivos.
Los Tres Tipos de Fuzzers
Cuando se trata de fuzzers de archivos, se pueden categorizar de varias maneras.
-
Un fuzzer puede ser basado en generación o en mutación, lo cual depende en gran medida de si las entradas se generan desde cero o mediante la modificación de entradas existentes.
-
Un fuzzer puede ser tonto o inteligente, lo cual depende en gran medida de si es consciente de la estructura de la entrada o no.
-
Un fuzzer puede ser de caja blanca, gris o negra, lo cual depende del nivel de conocimiento de la estructura del programa.
Escenarios de Uso
Una de las mejores y más comunes maneras en que se implementa el fuzzing como técnica automatizada es durante el proceso de exposición de vulnerabilidades en programas basados en seguridad.
La razón es prevenir que estos programas sean explotados con intenciones maliciosas, y el proceso de fuzzing de archivos se utiliza para mostrar la presencia de errores. De esta manera, cualquier error puede ser corregido y el programa hará eficientemente lo que se suponía que debía hacer desde el principio, proporcionar un nivel de seguridad más alto que nunca. Otra forma en que el fuzzing de archivos contribuye es a través de la exposición de errores.
Un fuzzer debe ser capaz de distinguir el comportamiento esperado o normal del programa del comportamiento inesperado o defectuoso del programa.
Una máquina no siempre puede distinguir un error de una característica, por lo tanto, en las pruebas automatizadas de software, esto se llama el problema del oráculo de prueba y es realmente fascinante. Para que un fuzzer distinga entre entradas que provocan fallos y las que no, generalmente busca la ausencia de especificaciones y utiliza una medida simple y objetiva.
Los fallos son fácilmente identificables y pueden indicar vulnerabilidades potenciales como una denegación de servicio, por ejemplo. Tenga en cuenta que la ausencia de un fallo no indica la ausencia de una vulnerabilidad. Un programa escrito en el lenguaje de programación C puede o no fallar si una entrada provoca un desbordamiento de búfer.
En este caso, el comportamiento del programa es indefinido. Para que un fuzzer sea más sensible a fallos distintos de los fallos, se pueden utilizar sanitizadores.
Estos pueden inyectar surtidos que hacen que el programa se bloquee cuando se detecta un fallo. Hay un desinfectante para cada categoría de errores, incluyendo aquellos que detectan errores relacionados con la memoria, como los que detectan comportamientos indefinidos, los que detectan condiciones raras y bloqueos, los que detectan fugas de memoria, los que detectan desbordamientos de búfer y, finalmente, los que verifican la integridad del flujo de control.
La seguridad del navegador también es un campo de pruebas extremadamente popular que implementa fuzzing. Es probable que el navegador que estás usando actualmente haya pasado por un riguroso fuzzing. El código Chromium utilizado en Google Chrome es continuamente sometido a fuzzing por el equipo de seguridad de Chrome, que tiene 15,000 núcleos a su disposición.
Un ejemplo completo:
import math
import random
import subprocess
import time
import os.path
from tempfile import mkstemp
from collections import Counter
# Archivos para usar como semilla de entrada inicial.
file_list = ["./data/pycse.pdf", "./data/PyOPC.pdf", "./data/003_overview.pdf",
"./data/Clean-Code-V2.2.pdf", "./data/GraphDatabases.pdf",
"./data/Intro_to_Linear_Algebra.pdf", "./data/zipser-1988.pdf",
"./data/QR-denkenswert.JPG"]
# Lista de aplicaciones para probar.
apps_under_test = ["/Applications/Adobe Reader 9/Adobe Reader.app/Contents/MacOS/AdobeReader",
"/Applications/PDFpen 6.app/Contents/MacOS/PDFpen 6",
"/Applications/Preview.app/Contents/MacOS/Preview",
]
fuzz_factor = 50 # 250
num_tests = 100
# ##### Fin de la configuración #####
def fuzzer():
"""Aplicaciones de fuzzing."""
stat_counter = Counter()
for cnt in range(num_tests):
file_choice = random.choice(file_list)
app = random.choice(apps_under_test)
app_name = app.split('/')[-1]
file_name = file_choice.split('/')[-1]
```python
buf = bytearray(open(os.path.abspath(file_choice), 'rb').read())
# Código del fuzzer de Charlie Miller:
num_writes = random.randrange(math.ceil((float(len(buf)) / fuzz_factor))) + 1
for _ in range(num_writes):
r_byte = random.randrange(256)
rn = random.randrange(len(buf))
buf[rn] = r_byte
# fin del código de Charlie Miller
fd, fuzz_output = mkstemp()
open(fuzz_output, 'wb').write(buf)
process = subprocess.Popen([app, fuzz_output])
time.sleep(1)
crashed = process.poll()
if crashed:
logger.error("El proceso falló ({} <- {})".format(app, file_choice))
stat_counter[(app_name, 'failed')] += 1
else:
process.terminate()
stat_counter[(app_name, 'succeeded')] += 1
return stat_counter
if __name__ == '__main__':
stats = fuzzer()
print(stats)La Cadena de Herramientas
Un fuzzer puede producir una gran cantidad de entradas en poco tiempo.
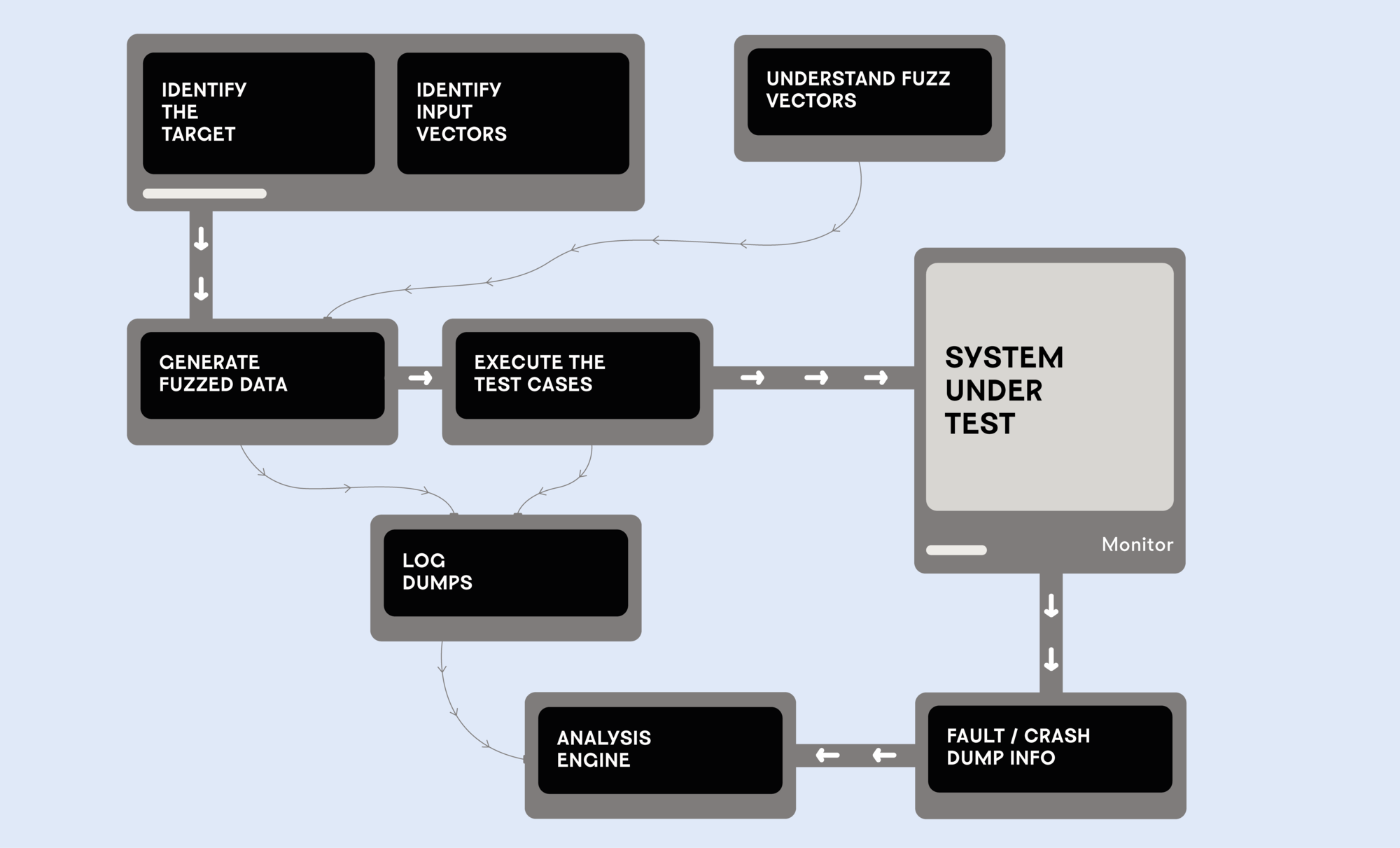
Como tal, la mayoría de los fuzzers comunes proporcionan cadenas de herramientas que automatizan tareas manuales que siguen a la generación automatizada de entradas que inducen fallos, ofreciendo muchas mejoras en la calidad de vida de todo el proceso.
Como tal, existe la clasificación automática de errores, que se utiliza para agrupar una gran cantidad de entradas que inducen fallos por causa raíz. Luego prioriza cada error individual por el nivel de gravedad.
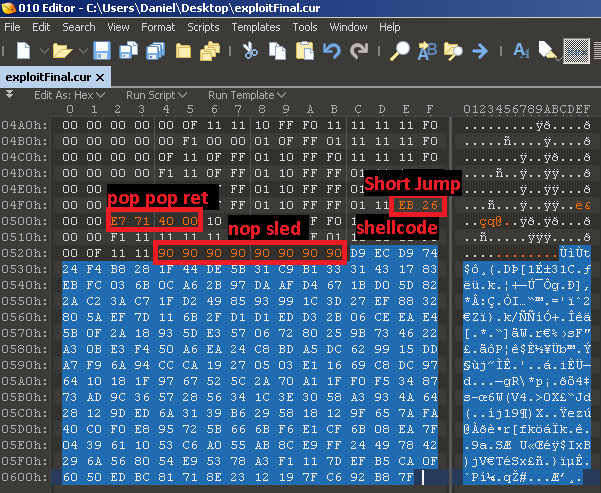
Como un fuzzer puede producir mayores cantidades de entradas, muchas de las que inducen fallos pueden efectivamente exponer el mismo error de software. Sin embargo, algunos de estos errores son críticos para la seguridad y necesitan ser corregidos con un nivel de prioridad más alto.
Otro hecho importante es que el Centro de Investigación de Seguridad de Microsoft, también conocido como MSEC, ha desarrollado la herramienta !exploitable, que puede crear un hash para una entrada que provoca un fallo, determinando su singularidad y asignándole una calificación de explotable, probablemente explotable, probablemente no explotable o desconocido.