

A veces necesitamos procesar toneladas de datos, pero escalar aplicaciones no es fácil, sobre todo en Python. Por eso comencé a investigar sobre el procesamiento de datos en tiempo real y descubrí Apache Storm. Apache Storm es una tecnología liberada como software de código abierto por Twitter para procesar datos en tiempo real. Esta es la forma en que pueden proporcionar, por ejemplo, los Temas de Tendencia.
Wikipedia: Apache Storm es un marco de computación de procesamiento de flujo distribuido escrito predominantemente en el lenguaje de programación Clojure
Básicamente, con Storm, puedes procesar, manipular y transformar flujos de tuplas de datos. Hay 3 conceptos importantes en Storm.
Spouts: estos son la fuente de los datos. En general, los spouts recuperarán los datos de un broker de colas como Apache Kafka o RabbitMQ, pero en realidad pueden usar cualquier fuente, por ejemplo, la API de Twitter.
Pernos: estos consumen entradas y producen salidas. Los pernos pueden recibir la entrada de surtidores pero también de otras entradas. La lógica va en el perno, por lo que podemos filtrar, unir, agregar,… los datos y también almacenar el resultado.
Topología: esto define cómo funcionan los surtidores y pernos, por lo que es posible describir cómo un surtidor recupera algunos datos y los envía a un perno que los enviará a otro y así sucesivamente. Las topologías se ejecutan indefinidamente cuando se despliegan.
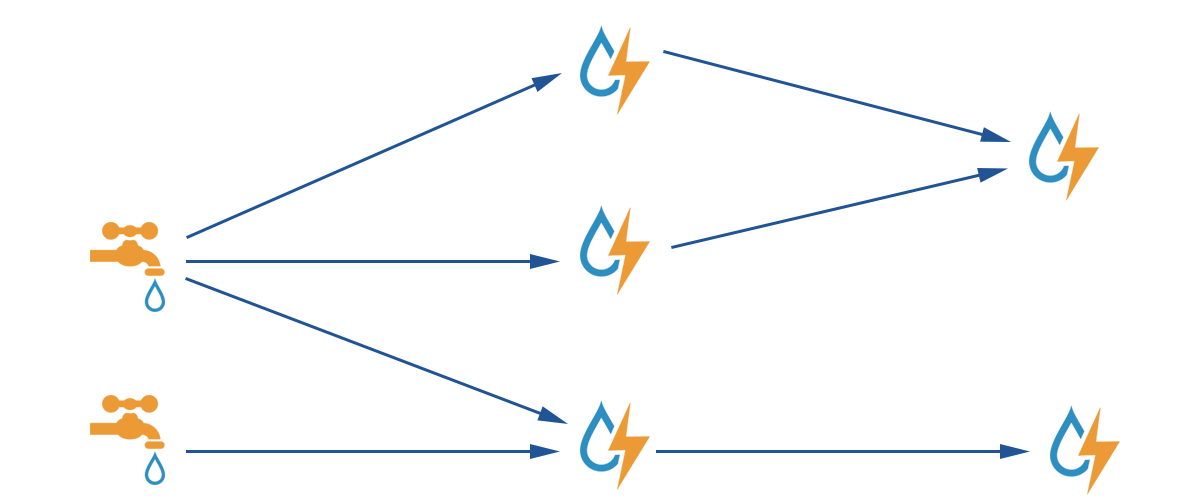
Figura 1: Ejemplo de topología
Una vez que tenemos nuestra topología, necesitamos desplegarla, para eso necesitaremos un clúster de tormenta. Los clústeres de tormenta están compuestos por diferentes componentes:
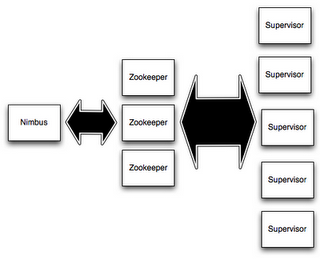
Figura 2: Topología de Apache Storm
- Nimbus es el demonio responsable de distribuir el código alrededor del clúster, asignar tareas a las máquinas y monitorear fallos.
- Supervisor escucha constantemente el trabajo asignado por nimbus.
- Zookeeper es un clúster por sí mismo. Proporciona sincronización de datos a través de los nodos. Nimbus y Supervisor son sin estado, por lo que todo el estado se mantiene en Zookeeper.
También podemos encontrar otro componente interesante: ui. La ui es una aplicación web básica para mostrar todos los detalles del clúster.
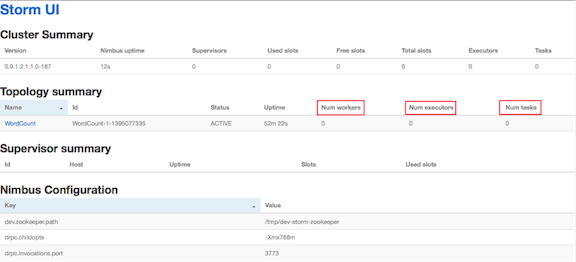
Figura 3: Apache Storm UI
![]()
Apache Storm admite Java y Python como lenguajes para la distribución y ejecución de código, sin embargo, encontré una biblioteca que facilita bastante la integración con Python: streamparse.
Veamos un ejemplo de proyecto, muy básico, para contar palabras. Este ejemplo está incluido en streamparse por defecto. Este es el spout:
from itertools import cycle
from streamparse import Spout
class WordSpout(Spout):
outputs = ['word']
def initialize(self, stormconf, context):
self.words = cycle(['dog', 'cat', 'zebra', 'elephant'])
def next_tuple(self):
word = next(self.words)
self.emit([word])En este ejemplo, el spout no está recuperando los datos de ningún lugar, simplemente los define en el método initialize(). Este método debe usarse para inicializar todas las variables y recuperar los datos o preparar los datos para ser recuperados. También necesitaremos implementar un método next_tuple() que obtendrá la siguiente pieza de datos y la convertirá en una tupla que queremos emitir al bolt. El objeto next_tuple() será invocado continuamente, por eso necesitamos inicializar las variables antes.
Este es el bolt:
import os
from collections import Counter
from streamparse import Bolt
class WordCountBolt(Bolt):
outputs = ['word', 'count']
def initialize(self, conf, ctx):
self.counter = Counter()
self.pid = os.getpid()
self.total = 0
def _increment(self, word, inc_by):
self.counter[word] += inc_by
self.total += inc_by
```python
def process(self, tup):
word = tup.values[0]
self._increment(word, 10 if word == "dog" else 1)
if self.total % 1000 == 0:
self.logger.info("counted [{:,}] words [pid={}]".format(self.total,
self.pid))
self.emit([word, self.counter[word]])También tenemos un método initialize(). Pero el método más importante es process(), que recibirá una tupla del spout y realizará la lógica. También emitirá una tupla resultado de la lógica.
La topología:
from streamparse import Grouping, Topology
from bolts.wordcount import WordCountBolt
from spouts.words import WordSpoutclass WordCount(Topology): word_spout = WordSpout.spec() count_bolt = WordCountBolt.spec(inputs={word_spout: Grouping.fields(‘word’)}, par=2)
Como puedes ver, esta topología llamada WordCount describe cómo el word_spout será la entrada para el bolt. Por defecto, la tupla puede ser enviada a cualquier ejecutor, pero podemos cambiar este comportamiento usando 'Grouping'. En este ejemplo, estamos enviando todas las tuplas con el mismo campo 'word' al mismo ejecutor siempre, para que pueda contar todas las palabras que son iguales. También usará 2 instancias paralelas de este bolt a lo largo de todo el clúster.
\[bctt tweet="Procesamiento en tiempo real con Python #python #distributed" username="jpalanco"\]
He creado una infraestructura de docker composer, por lo que será muy fácil hacerlo funcionar. Puedes descargarlo desde: [https://github.com/jpalanco/streamparse-wordcount-docker-compose](https://github.com/jpalanco/streamparse-wordcount-docker-compose)
git clone https://github.com/jpalanco/streamparse-wordcount-docker-compose.git cd streamparse-wordcount-docker-compose docker-compose scale supervisor=4 docker-compose up -d
Puedes ver cómo se despliega la topología y cuenta palabras en Python usando la interfaz en [http://127.0.0.1:49080/](http://127.0.0.1:49080/)
¡Feliz programación!